
인공지능 기술의 개발로 국립생물자원관이 보유하고 있는 생물종에 대한 이미지, 사운드, 영상 등 다양한 멀티미디어 빅데이터의 활용 기반이 마련되었다.
비교적 쉽게 데이터 확보가 가능하며 종동정이 용이한 매미소리를 선정하여 소리로 종을 분류할 수 있는 프로그램을 개발하였다.
먼저 매미 소리 학습을 위해 매미 소리를 현장에서 수집하였다.
소리 데이터는 이번 사업을 진행하며 채집한 소리와 이전에 채집된 데이터를 확보하여 활용하였다.
| 순번 | 조사장소 | 장비 설치 좌표 | 고도 |
|---|---|---|---|
| 1 | 평창군 대화리 산190 무덤가 개활지 |
37˚29´14˝N 128˚27´29˝E |
440m |
| 2 | 평창군 대화리 166 정상 능선 개활지 |
37˚30´13˝N 128˚27´26˝E |
520m |
| 3 | 평창군 대화리 1092-1 언덕 개활지 |
37˚30´22˝N 128˚26´7˝E |
610m |
| 4 | 영월군 방절리 산151-1 무덤가 개활지 |
37˚12´11˝N 128˚26´17˝E |
320m |
| 5 | 정선군 남면 무릉리 산92-4 언덕 개활지 |
37˚16´14˝N 128˚46´60˝E |
860m |
| 6 | 정선군 남면 유평리 산306 임도 무덤가 |
37˚16´21˝N 128˚45´45˝E |
840m |
| 7 | 평창군 대화리 산572 경작지 주변 개활지 |
37˚31´4˝N 128˚26´49˝E |
540m |
| 8 | 평창군 대화리 산565 법장사 인근 개활지 |
37˚31´14˝N 128˚26´29˝E |
600m |

| 종 | 파일 수 | 총 재생 시간 |
|---|---|---|
| 소요산매미 | 34 | 2:41:32 |
| 털매미 | 21 | 4:53:38 |
| 유지매미 | 7 | 2:52:09 |
| 말매미 | 25 | 4:21:53 |
| 애매미 | 64 | 6:33:49 |
| 쓰름매미 | 17 | 2:46:48 |
| 참매미 | 26 | 4:23:51 |
| 참깽깽매미 | 17 | 2:32:20 |
| 늦털매미 | 15 | 3:29:06 |
| 풀매미 | 10 | 2:37:48 |
| 호좀매미 | 14 | 2:44:10 |
| 세모배매미 | 16 | 2:31:10 |
녹음된 데이터는 학습에 적절하지 않은, 매미소리가 중복으로 녹음되어 있거나 잡음이 들어가거나 소리가 작은 경우 데이터 전처리 과정을 거쳐 필터링을 하였다.
어도비 오디션을 사용하여 녹음 파일을 듣고 수작업으로 학습에 불필요한 부분을 잘라내었다.
인공지능 학습용 데이터 품질관리 가이드라인 v2.0을 준수하여 작업하였다.
| 학습데이터 정규화 | |
|---|---|
| 샘플링 주파수 | 44.1 kHz |
| 심도 | 16bit |
| 채널 | 모노 |
전처리된 소리 데이터는 최대 1분 길이로 분할하여 종 별로 구축하여 추후 다른 연구에도 활용 할 수 있도록 제공 예정이다.
사업 초기에는 오디오의 스펙트로그램 이미지를 활용한 딥러닝만 진행하려 했으나, 여러 방법을 활용하기로 결정하였고, 오디오의 특성정보를 이용한 머신러닝도 진행하였다.
딥러닝에는 tensorflow를 사용하였고 머신러닝은 librosa 라이브러리를 사용하였다.
매미 소리 종동정 모델 학습은 tensorflow 2.8 버전과 python 3.8 버전을 사용하였다.
사업초기 스펙트로그램 이미지 딥러닝에 4가지 모델을 선정하였고, 자문의견을 바탕으로 CRNN 모델, 전이학습 모델을 추가하였다.
| 명칭 | 특징 |
|---|---|
| CNN (합성곱 신경망) |
|
| RNN (순환 신경망) |
|
| CRNN (합성곱 순환 신경망) |
|
| Transfer Learning (전이학습) |
|
데이터를 정제하면서 생산된 일부 데이터로 학습을 진행하였고 최종적으로 CNN, CRNN을 사용하여 학습을 진행하였다.
수집과 전처리를 통해 구축한 학습데이터를 1초, 3초, 5초, 7초 간격으로 분할하여 스펙트로그램 이미지로 변환하였다.



분할 시간이 늘어나면 스펙트로그램 이미지가 합쳐지고 데이터 수가 줄어들어 학습 효율이 좋지 않아 1초 간격 분할을 선택하였다. 분할된 스펙트로그램 이미지 개수는 65,455개이다.




training data / valid data / test data를 8 : 1 : 1 비율로 생성하였다.
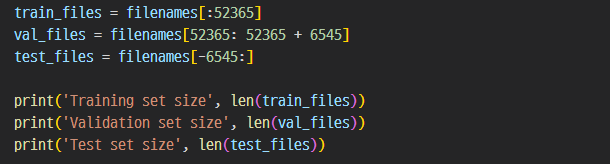
| data set | training data | valid data | test data | total data |
|---|---|---|---|---|
| 개수(1초 wav) | 52,365 | 6,545 | 6,545 | 65,455 |
CNN 모델과 CRNN 모델을 사용하여 검증 및 테스트 세트에 대해 훈련 세트 전처리를 반복하였다.
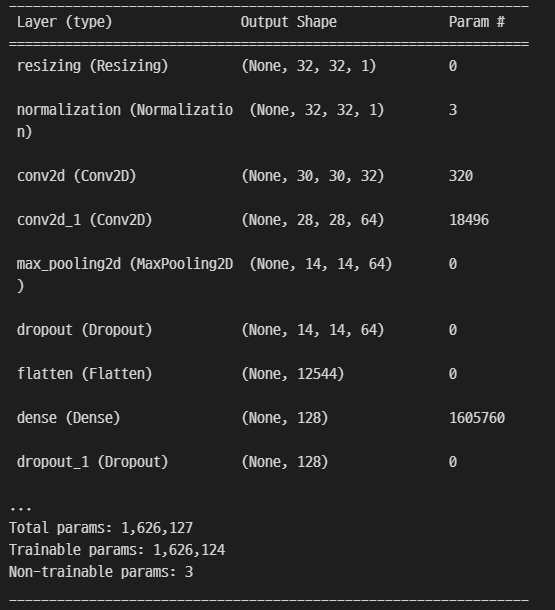
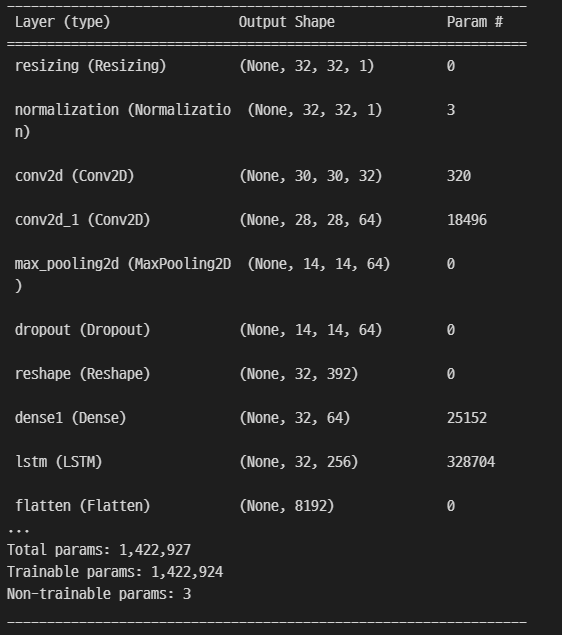
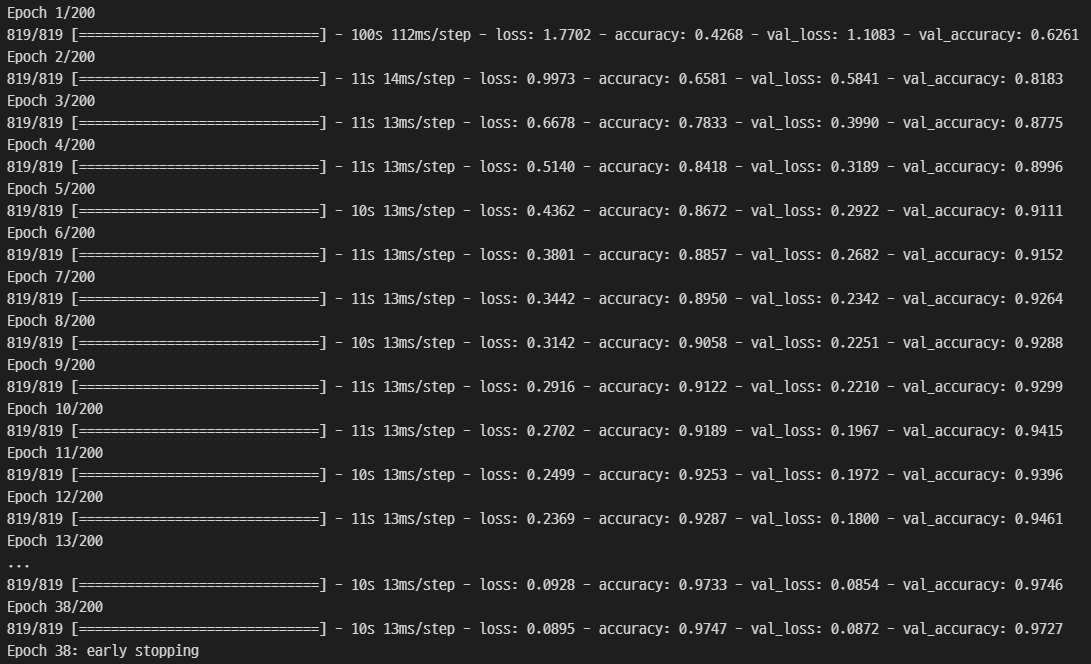
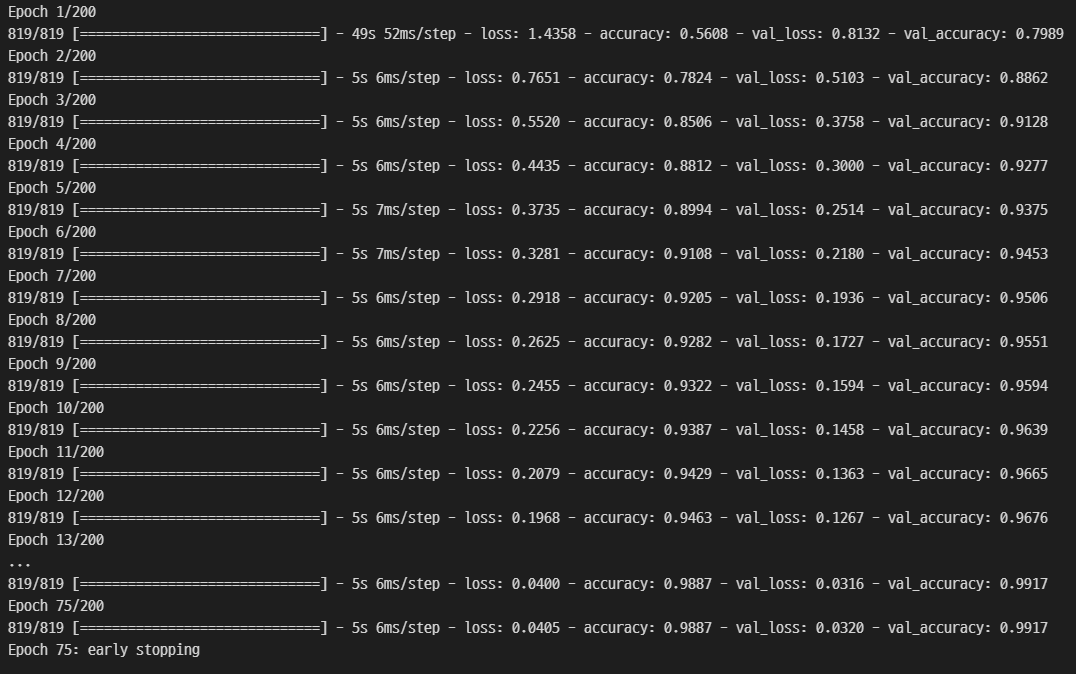
| Model | Batch size | Learning Rate | Epochs | Validation Set Accuracy |
|---|---|---|---|---|
| CNN | 32 | 0.001 | 38 | 97.27% |
| CRNN | 32 | 0.001 | 75 | 99.17% |
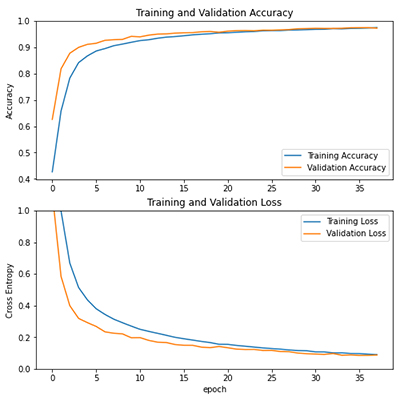
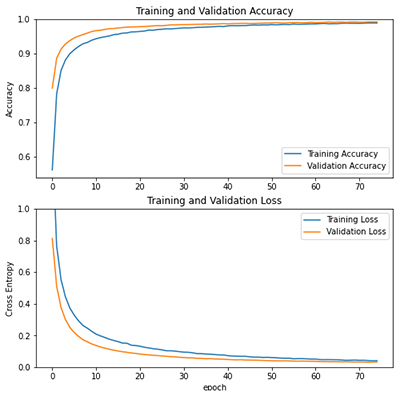
CNN과 RNN 모델이 합쳐진 CRNN 모델이 CNN모델보다 정확도가 높게 출력되어, CRNN 모델을 대민 서비스에 활용하기로 하였다.
특성정보를 이용한 머신러닝은 python 3.8 버전와 scikit-learn 1.0 버전을 사용하였다.
머신러닝 알고리즘은 많이 사용되고 있는 SVN, RandomForest, GradientBoosting, XGB 네 가지를 사용하였다.
파이썬에서 음원데이터를 분석할 수 있는 librosa 라이브러리를 사용하여 다음 표의 특성정보를 추출하였다.
| 명칭 | 특징 |
|---|---|
| tempo | BPM (beats per minute) |
| Chroma Frequencies | 음높이 계산 |
| RMS | 진폭의 제곱 평균 제곱근 |
| Spectral Centroid | 스펙트럼 중심 (음색과 관련) |
| Spectral Bandwidth | 스펙트럼 대역 폭 |
| Roll off | roll off 빈도 (주파수에 따른 전달 함수의 기울기) |
| Zero Crossing Rate | 신호가 변하는 속도 |
| Harmonic and Percussive Components | 고조파 요소 |
| Mfcc | 타악기 요소 |
| Melspectrogram | Spectogram의 y축을 Mel Scale로 변환한 것 |
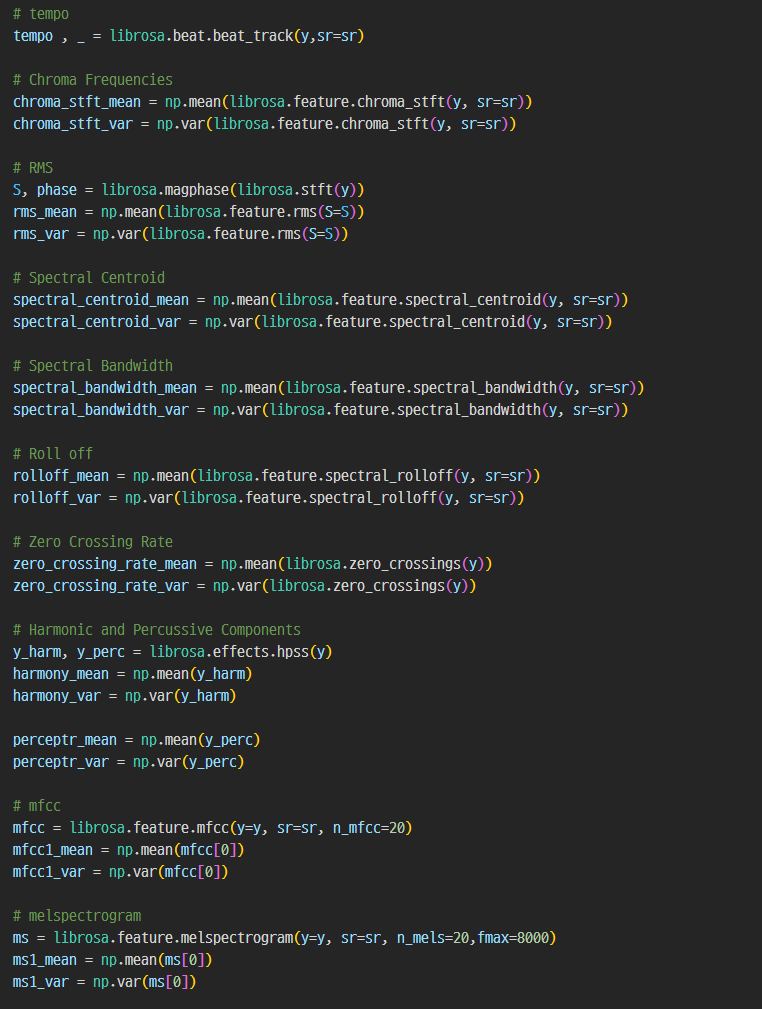
특성정보를 추출하기 위해 학습데이터를 8초 단위로 분할하여 training data / valid data / test data를 8 : 1 : 1 비율로 생성하였다.
| 학습데이터 | ||||
|---|---|---|---|---|
| data set | training data | valid data | test data | total data |
| 개수(8초 wav) | 7,247 | 900 | 900 | 9,049 |
특성정보를 추출하여 4가지 머신러닝 알고리즘으로 학습을 진행하였다.
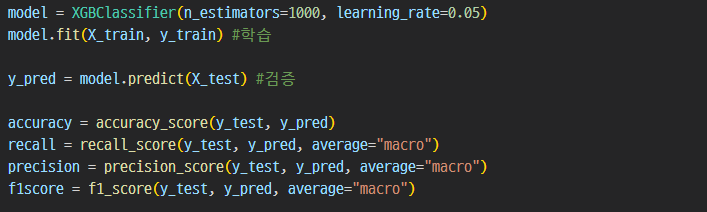
Accuracy (정확도), Recall (재현율), Precision (정밀도), F1 Score (테스트의 정확도) 네 항목을 측정하였다.
| Model | Accuracy | Recall | Precision | F1 Score |
|---|---|---|---|---|
| SVM | 89.17% | 87.07% | 89.98% | 88.29% |
| RandomForestClassifier | 97.13% | 96.42% | 97.14% | 96.75% |
| GradientBoostingClassifier | 98.29% | 98.15% | 98.49% | 98.31% |
| XGBClassifier | 98.95% | 98.86% | 99.03% | 98.94% |
XGBClassifier 알고리즘이 가장 높은 측정값을 보여주었다.
사용자가 매미소리를 업로드 했는지 혹은 다른 소리를 업로드 했는지 딥러닝 전 확인하는 과정을 추가하였다.
Uabansound8K 데이터 세트를 사용하여 필터링 과정을 만들었다.
CRNN 모델을 사용한 딥러닝과 특성정보를 활용한 머신러닝으로 예측을 해본 결과 CRNN 모델을 사용한 딥러닝이 더 정확한 예측을 보여주었다.

